Workplace Learning Analytics
EmployID is an EU-funded, four-year project which aims to support Public Employment Services staff to develop competences that address the need for integration and activation of job seekers in fast changing labour markets. According to the official flyer: “It builds upon career adaptability and resilience in practice, including quality and evidence- based frameworks for enhanced individual and organisational learning. It also supports the learning process of PES practitioners and managers in their professional identity development by supporting the efficient use of technologies to provide advanced coaching, reflection, networking and learning support services as well as MOOCs.”
One of the aims for research and development is to introduce the use of Learning Analytics within Public Employment Services. Although there is great interest in Learning Analytics by L and D staff, there are few examples of how Learning Analytics might be implanted in the workplace. Indeed looking at research reported by the Society for Learning Analytics Research reveals a paucity of attention to the workplace as a learning venue.
In this video, Graham Attwell proposes an approach to Workplace Learning Analytics based on the Social Learning Platform model (see diagram) adopted by the Employ ID project. He argues that rather merely fathering together possible data and then trying to work out what to do with it, data needs to be sought which can answer well designed research questions aiming to improve the quality of learning and the learning environment. 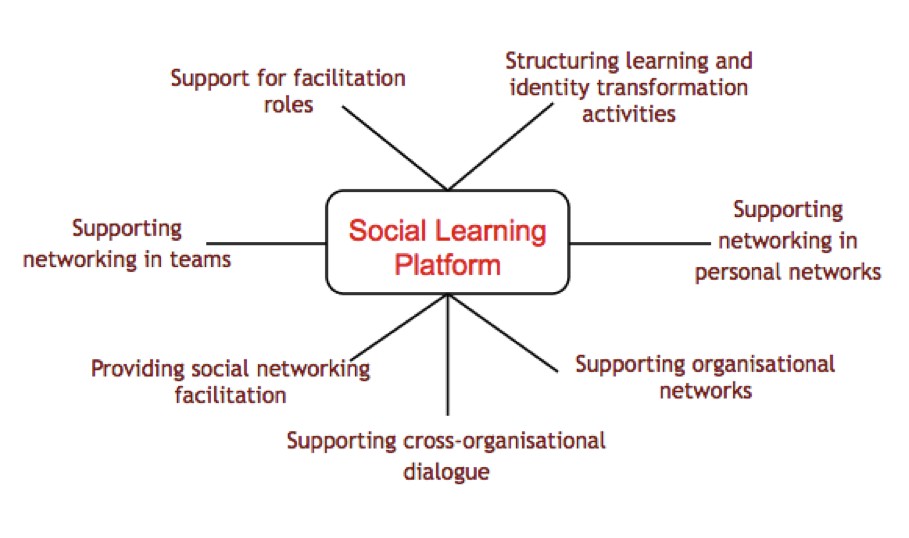
In the case of EmployID these questions could be linked to the six different foci of the Social Learning Platform, namely:
- Support for facilitation roles
- Structuring identity transformation activities
- Supporting networking in personal networks
- Supporting organisational networks
- Supporting cross organisational dialogue
- Providing social networking facilitation
- Supporting networking in teams
For some of these activities we already have collected some “docital traces” for instance data on facilitation roles through within a pilot MOOC. In other cases we will have to think how best to develop tools and approaches to data gathering, both qualitative and quantitative.
The video has been produced to coincide with the launch of The Learning Analytics Summer Institute, a strategic event, co-organized by SoLAR and host institutions and by a global network of LASI-Locals who are running their own institutes.